


1. Introduction
In the next months, public institutions and governments will certainly start regulating the non-regulated activities of cryptocurrencies such as Bitcoin or Ether. Some governments already claimed they were investigating cryptocurrencies activities [1-3]. These regulations will probably introduce new sets of rules and ask for more transparency among the blockchain players. As a result, financial products would probably require key information document to advise potential investors of the risk of these investments. Ethereum, with already more than one million accounts, is one of the major platforms for smart contracts relying on Ether cryptocurrency for its existence. Still, the platform supports very few documentation about how blockchain players interact. It also lacks of transparency for non-specialists. Modeling smart contracts and predictive analytics is thus essential for future regulation purpose. Our contributions are twofolds:
- We describe Paratuck2 Tensor Decomposition (TD) for smart contracts. A non-negative scheme is presented to determine a set of latent factors, where a huge multi-dimensional matrix is decomposed into a less dimensional structure.
- A second contribution is the prediction of smart contracts activities using Long Short Term Memory (LSTM) trained on Paratuck2 TD. The main novelty is the prediction of future activities by using a set of latent factors. We used LSTM since it has been shown to learn from both long term and recent observations.
We describe the theoretical foundations of our approach in the section materials and methods. We explain how our approach is applied to smart contracts profiling. Then, the results and discussion section highlights the predictions of Ethereum smart contracts exchanges over time. Finally, we conclude with pointers to future works.
2. Materials and Methods
The first tensor decomposition, the Candecomp/Parafac has been introduced in [4] and [5]. It has been followed then by more complex decomposition [6] that were used for large scale latent analysis [7], [8]. The Paratuck2 decomposition, introduced in [9], was used by Bro in [10] for food analysis and in [11,12] for signal analysis.
In parallel, LSTM networks were introduced in [13] to solve the problem of vanishing gradients of Recurrent Neural Networks (RNN) [14]. It has opened a wide range of applications domains for predictive analytics, space analytics and trajectories modeling [15-17].
Consequently, we present the theoretical tensor background, and then the novel non-negative scheme for the Paratuck2 resolution. Finally, we explain how to perform latent predictions with LSTM.
2.1 Mathematical Foundations
Terminology in this paper follows the one described by Kolda and Bader in [18]. Scalars are denoted by lower case letters, a. Vectors and matrices are described by boldface lowercase letters and boldface capital letters, respectively a and A. High order tensors are represented using upper case letter notation such as X.
The transpose matrix of A Є RI×J is denoted by AT.
The Moore-Penrose inverse of a matrix A Є RI×J is denoted by
X is called a n-way tensor if X is a n-th multidimensional array. It is expressed by
X is called a n-way tensor if X is a n-th multidimensional array. It is
expressed by
The square root of the sum of all tensor entries squared of the tensor X defines its norm.
The rank-R of a tensor
with the symbol
The Kronecker product between two matrices A Є RI×J and B Є RK×L,
denoted by
The Khatri-Rao product between two matrices A Є RI×K and B Є
RJ×K, denoted by
2.2 Non-Negative Paratuck2
The Paratuck2 decomposition, [9], is well suited for the analysis of intrinsically asymmetric relationships between two different sets of objects. It represents a tensor X Є RI×J×K as a product of matrices and tensors.
A, H and B are matrices of size RI×P, RP×Q, and RJ×Q. The matrices
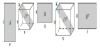
To achieve the computation of the Paratuck2 decomposition, the following minimization equation has to be solved
with
To solve equation 6, the Alternating Least Squares (ALS) method is used as presented by Bro in [10]. All of the matrices and the tensors are updated iteratively. To simplify the resolution explanation, we consider one level k of K, the third dimension of the tensor.
To update A, equation 5 is rearranged such that
The simultaneous least square solution for all k leads to
To update DA, equation 5 is rearranged such that
The matrix
The notation (k, :) represents the k-th row of
To update H, equation 5 is rearranged such that
which brings the solution
To update B and DB, the methodology presented for the update of A and DA is applied respectively.
In the experiments, we use the non-negative Paratuck2 decomposition leveraging the non-negative matrix factorization presented by Lee and Seung in [19]. The matrices A, B and H, and the tensors DA and DB are computed according to the following multiplicative update rule.
with
The non-negative multiplicative update rule helps to better calibration of LTSM since it uses the elements of the tensor decomposition as a starting point. Hereinafter is the complete algorithm of the non-negative ALS Paratuck2 resolution.
Algorithm 1 Non-Negative ALS Paratuck2 with P and Q latent components for a tensor X of size I × J × K
- procedure NN-PARATUCK2(X, P , Q)
- random initialization A Є RI×P, H Є RP×Q, B Є RJ×Q
-
set
- X = [X1 X2...Xk]
- x = vec(X)
- repeat:
-
-
-
-
-
- until maximum number of iterations or stopping criteria satisfied
2.3 Latent LSTM predictions
Based on the notation of Sak et al. in [20], LSTM contains memory
blocks in the recurrent hidden layer. Each memory block is connected
to an input gate and an output gate. Similarly to RNN, the input gate
plays the role of the input activation of the memory cells. The output
gate is in charge of the flow of cell activations into the rest of the
network. In addition, a forget gate is added to the memory block
since Gers, Cummins and Schmidhuber presented it in [21]. The
forget gate allows the reset of the cell’s memory depending on the
information received through the input gate. If we consider the input
sequence denoted by x such as x = (x1,...,xT), the output sequence
denoted by y such as y = (y1,...,yT) for a sequence of events from t = 1
to t = T. The mapping between x and y for all network unit activations
within LSTM is described by the set of equations (15). The activation
of the input gate is denoted by it, the candidate value for the states of the
memory cells by
In the set of equations 15 at time t, xt stands for the memory cell layer, Wk and Uk with k= {i, c, f, o} for the weight matrices and bk for the bias vectors. In the model used for the experiments, the activation of a cell’s output gate is independent of the memory cell’s state Ct such that V0 = 0. The main advantage by fixing V0 = 0 is the ability to perform faster computation, especially on large datasets.
With regards to figure 1, the tensors DA and DB collects data about the tensor factorization related to the third dimension, which is very often the time. It means that the evolution of each groups, or clusters, characterized by the latent factors P and Q of the TD contained in the tensors DA and DB can be modeled using LSTM. More precisely, LSTM is calibrated on the historical data of the tensors DA and DB to predict afterwards the future evolution of each P and Q groups contained in the tensors DA and DB as illustrated in figure 3.
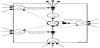
Only the diagonals of the tensors Dm with m = {A, B} contain numbers.
Therefore, the tensors Dm Є RL×L×K can be reduced to a matrix, E Є RL×K.
The notation L = {P,Q} denotes the latent factors of the Paratuck2 TD.
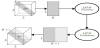
Data contained in E is then used to train LSTM before performing the
predictions on an interval Є related to the third dimension K. The
resulting matrix of size RL×(K+Є) gathers the historical data of each latent
component L as well as the predicted values. A new tensor denoted by
3. Results and Discussion
In this section, we apply our multidisciplinary tensor neural network approach, Paratuck2-LSTM, for Ethereum smart contracts profiling. The experiment is performed on a machine with 15 Intel Xeon E5-4650 v4 2.20 Ghz CPU cores and 80 GB of RAM. We have implemented in Python the algorithm for non-negative Paratuck2 decomposition combined with LSTM code available in [22].
3.1 Application to Smart Contracts
Smart contracts activities have been extracted from the Ethereum platform. The data was collected starting 1 January 2016 and ending 1 July 2016. Through the collection process, different data types have been stored, such as the hash key, the sender accounts, the receiver accounts or the blockheights. For the considered six months period, more than 5 millions of transactions have been made. This accounts for an average of 26 transactions per sender account and 18 transactions per receiver account.
In the data set, some smart contracts only relate to one transaction, payment or reception. Such behavior is difficult to predict, and should be considered as unexpected behavior. Our aim is to predict future interactions based on exchanges that already happened. Consequently, only the 1% most active smart contracts have been kept in the training set for their regular activities. This represents a list of 100 smart contracts sending an Ether amount, and a list of 200 smart contracts receiving an Ether amount from the sender contracts.
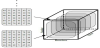
The features extracted from the dataset are well suited for a tensor representation. Two tensors denoted by X Є RI×J×K are built from the Ethereum data. The first dimension, I, lists the sender accounts, the second dimension J, the receiver accounts and the third dimension, K, the time. For each tensor, the interaction between a sender and a receiver is represented by the amount of Ether exchanged at a time. The dense tensor is built based on figure 4. The size of the tensor is R100×200×50. The tensor is decomposed to highlights the latent component over time. Then, LSTM latent predictions are performed.
As illustrated in figure 5, the information evolving over time is contained in the tensors Dm with m= {A, B}. The matrix A gathers static information regarding P senders groups and the matrix B static information regarding Q receivers groups. The matrix H contains the asymmetric information between the P and the Q latent factors which have been set to respectively to 20 and 30. As a result, the LSTM network is trained on Dm for the sender and the receiver activities predictions.
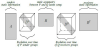
3.2 Predictions results
Figures 6 and 7 show the difference between the true experimental data and the predictions for one rank of the tensors DA and DA. The LSTM predictions of smart contracts activities are close to the one observed in the tensor decomposition of the complete true dataset. It means LSTM is appropriate for the modeling of the smart contracts having regular exchanges. To further quantify the accuracy of LSTM predictions, statistical tests are performed. The mean absolute percentage error (MAPE) and the mean directional accuracy (MDA) are computed betwen the predictions and the true data set. A third measure, the Jaccard distance, is also evaluated. As a benchmark for LSTM predictions, the results are compared to the predictions performed by a Decision Tree (DT).


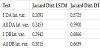
Tables 1 and 2 highlights similar MAPE results for both LSTM predictions and DT predictions. Differences are not significant. On the other hand, the MDA score is lot higher, around a factor 7, for LSTM predictions than for DT predictions. It means the LSTM predictions are able to better reproduce the variations observed in the smart contracts activities through time than the DT predictions. From these first statistical tests, we can observe that the LSTM model is able to reproduce the changes over time of smart contracts activities. It outperforms the decision tree benchmarking algorithm. In addition, the Jaccard distance is computed to underline the distribution divergence between the predictions and the true experimental data. In table 3, it can be observed that LSTM predictions are significantly closer to the true experimental distribution than DT predictions. All LSTM Jaccard distances are within the range 0.20 and 0.30 while the DT Jaccard distances are between 0.57 and 0.69. LSTM Jaccard distances are between 2 to 3 times lower than the DT Jaccard distances. It confirms the MDA scores in tables 1 and 2.


From the highlighted results, the combined approach of Paratuck2- LSTM delivered good results, validated visually and statistically. It outperformed the DT benchmarking for predictive analytics on several statistical criteria including the MDA and the Jaccard distance.
4. Conclusion
We proposed in this paper a multi-disciplinary approach leveraging multidimensional linear algebra and neural networks for modeling the complex activities occurring on a certain type of blockchains. Our method combines Paratuck2 tensor decomposition and LSTM to predict behavior in relation to asymmetric data over time. The asymmetry is expressed within the tensor decomposition using two sets of latent factors related to two sets of objects. Our use case considered sender and receiver contracts of the Ethereum platform. Our approach allowed to detect common behaviors over time. Furthermore, it was able to predict accurate interactions and exchanges. We validated our results using statistical tests.
Although the method showed good results in terms of accuracy, it currently lacks the required scalability to be used on big data sets. This is due to the non-negative ALS update rule which is time and memory consuming. We plan to address in future works this issue and develop additional resolution method to the Paratuck2 tensor decomposition using other iterative schemes. Last but not least, the better scalability of the method would help to increase the accuracy of the LSTM network as the training could be performed on longer time period and smaller time step discretization. We plan to address a particular use-case about fraud detection and detection of suspicious behavior over time.
Competing Interests
The authors declare that they have no competing interests.
Acknowledgments
The authors would like to thank Beltran Borja Fiz Pontiveros for his help in Ethereum data manipulation.