


1. Introduction
Advances in networking technology and an increase in the need for computing resources have persuaded many organizations to outsource their storage and computing needs. This new economical computing and storage model is commonly referred to as Cloud computing. Cloud infrastructures can be roughly categorized as either private or public. In a Private Cloud, the infrastructure is managed and owned by the customer and located on premise. This means the access to customer data is under its control and is only granted to parties it trusts. On the other hand, in a Public Cloud, the infrastructure is owned and managed by a cloud service provider and is located offpremise. This implies that the customer data is outside its control and could potentially be granted to untrusted parties.
By moving their data/computing to the Cloud, customers can avoid the costs of building and maintaining a private Information Technology (IT) infrastructure, opting instead to pay a service provider as a function of its needs. For most customers, this provides several benefits including availability (i.e., being able to access data from anywhere and at any time) and reliability (i.e., not having to worry about backups) at a relatively low cost.
While the benefits of using a Public Cloud infrastructure are clear, it also introduces significant security and privacy risks. In fact, it is well-recognized that the biggest hurdle to the adoption of Cloud storage (and Cloud computing in general) is the concern over the confidentiality and integrity of data. For example, data leakage issue in the Cloud, caused by malicious adversaries or misbehaving Cloud operators, is a big threat to customers’ important and/or sensitive data like business secrets or personal health records. The leakage of celebrities’ photos in iCloud is a well-known example. The privacy of the involved celebrities has been seriously infringed in these events. Although, lots of consumers may be willing to trade their privacy for the convenience of software services (e.g., web-based email, social activities, calendars, pictures, etc.), it is our belief that, this is not the case for enterprises and government organizations. The General Data Protection Regulation (GDPR) [1] has been approved by the European Union and, once it comes into force in 25 May 2018, will give data subjects significant new rights over how their personal data is collected, processed, and transferred by data controllers and processors. It demands significant data protection safeguards to be implemented by organizations. This newly harmonized Europeanwide regulation mandates the protection of data about people living in the European Union, by every organization that controls or processes data on people in the EU, regardless of where that organization is located around the world. Clearly, the adoption of GDPR in EU gives the best evidence of our previous claim.
To protect the sensitive data, a common remedy for data leakage is: data owner encrypts all the data with their own key before uploading them to cloud server. In this way, people who are not authorized by the data owner cannot retrieve and decrypt the data stored on Cloud server. The Cloud storage equipped with this kind of protection is called the cryptographic Cloud storage.
After encrypting all the data stored on the Cloud server, searching the stored data brings forth a new challenge. Due to the loss of data’s original properties, it is hard to search the encrypted data directly. Therefore, Song, Wagner, and Perrig proposed the first searchable encryption (SE) scheme in 2000 [2]. In the scheme, data owner encrypts the involved keywords and uploads them to Cloud server together with the corresponding encrypted data. For retrieving a keyword matched data, user sends the corresponding trapdoor function of the keyword to the Cloud server for performing search over the encrypted data. In this way, the search in the ciphertext domain becomes desirable and feasible.
A lot of literatures on the subject of SE have been published nowadays. However, some important issues about the practical usage of SE schemes are usually ignored in those literatures. Although combining cryptographic cloud storage and searchable encryption scheme can achieve the basic security requirements of a Cloud storage, some challenges, such as secure communication, storage requirement, and computational complexity, still render SE schemes impractical and inefficient.
A typical example of the impracticality caused by the limited storage capacity is in the applications with lightweight mobile devices. This challenge comes from the fact that in traditional SE schemes the required key size is usually proportional to the number of involved attributes. The limited memory capacity of lightweight devices, such as mobile phones and smart watches, has become a bottleneck for enabling some security related applications, especially when the number of involved attributes is getting larger.
In this work, a multi-user SE scheme with constant-size keys is proposed. In our scheme, the size of keys is independent of the number of the user’s attributes. Since the key size is constant and small, our scheme is allowed to be applied to all applications even with limited key storage, such as in lightweight devices. Moreover, the proposed scheme provides efficient mechanisms for the participation and the revocation of a user. For example, it is easy to process the participation and leave of students or staffs of a school. Therefore, it can be easily applied to storage management systems of an organization with data security concerns. We also analyze and investigate the security level of our scheme and present the corresponding executional performance. Finally, a prototype system based on the proposed scheme has been built to verify the feasibility of our work.
2. Related Work
2.1 Searchable Encryption
As we have mentioned in Section 1, the concept of SE scheme was first introduced in [2]. The authors also presented the first practical symmetric searchable encryption (SSE) scheme in that paper. In that SSE scheme, each encrypted document is embedded with a keyed hash for each keyword and the server can search for keywords by recalculating and matching with the hash values. Later, Boneh, Di, Ostrovsky, and Persiano proposed the first asymmetric searchable encryption (ASE) scheme based on the Bilinear pairing in [3]. In the ASE scheme, every customer can use the public key to encrypt the data and keywords but only the user who has the private key can search and decrypt the encrypted data.
Single-user searchable encryption (SUSE) scheme allows only one user in the system. That is to say, the only legal user is the data owner, he himself. It is obvious that SUSE scheme is extremely impractical. In 2006, Curtmola, Garay, Kamara, and Ostrovsky proposed the first symmetric multi-user searchable encryption (MUSE) scheme [4], which made use of an SUSE for keyword search and a broadcast encryption (BE) for key management and user management. In that scheme, data owner is the broadcaster and the group users with keyword search permission are receivers. Data owner shares the key of SUSE to receivers to achieve the goal of multi-user search ability. However, sharing key will lead to the leakage of the key when an untrusted server colludes with revoked users. Later, Bao, Deng, Ding, and Yang proposed an MUSE scheme based on Bilinear pairing in [5]. Their scheme allows every customer in the system to generate the encrypted data and keywords and everyone also can search the data for any keyword. However, [5] did not take the critical requirement of access control into account.
Subsequently, a number of various SE schemes have been proposed for different purposes, including using conjunctive keyword search [13,14] or fuzzy keyword search [15,16] to extend the searching functionality, such as using the scheme against inclusion-relation attacks to improve the security [17,18], and using logarithmic-time search to improve the operational efficiency [19]. Moreover, Lv, Zhang, and Feng proposed an MUSE scheme by using the Ciphertext-Policy Attributed-Based Encryption (CP-ABE) scheme, which provides an efficient access control scheme for Cloud storage applications [12].
2.2 Encrypted Access Control for Cloud Storage
In 1984, Shamir introduced the notion of identity-based (IDbased) cryptography and presented a concrete signature scheme [6]. The major merit of an ID-based cryptosystem is that the public key can be an arbitrary string. Therefore, the public key can be set using user’s identification information, such as telephone number or email address. Although [6] successfully constructed an ID-based signature, it did not work out how to construct an ID-based encryption (IBE) scheme. This problem had remained open until Boneh and Franklin introduced the notion of bilinear pairings and successfully constructed a concrete ID-based encryption scheme in [7]. Based on it, many IBE schemes with further enhancements have been proposed. These include signature schemes, key establishment schemes, functional (or attribute-based) encryption, and privacy-enhancing techniques such as anonymous credentials. Pairing-based cryptography has also been adopted commercially. The two largest companies in this field are Voltage Security and Trend Micro.
Attribute-based encryption (ABE) scheme is an extension of IBE scheme which allows user to encrypt and decrypt messages based on attributes and access structures. ABE scheme was first introduced by Sahai and Waters in [8]. There are mainly two kinds of ABE schemes: Key-Policy ABE (KP- ABE) [9] and Ciphertext-Policy ABE (CP-ABE) [10]. In a KP-ABE scheme, a ciphertext is associated with a set of attributes and a user’s key can be associated with an access structure, which can be a logic composition of attributes, for example. The ciphertext can be decrypted with the user’s key if and only if the attribute set of ciphertext satisfies the access structure associated with the user’s key. At the end of [9], the authors also suggested the possibility of building a CP-ABE scheme, but did not give any realistic construction.
In 2007, Bethencourt, Sahai, and Waters proposed a CP-ABE scheme [10]. They also provided an implementation of their system, which included several optimization techniques. In a CP-ABE scheme, a ciphertext encrypts a message with an access structure while a user’s key is associated with a set of attributes. A user can decrypt the ciphertext if and only if the attribute set fulfils the access structure. For example, suppose that a teacher delivers a course for computer science in NTU. After midterm test, he may want to encrypt the midterm result so that only personnel that have credentials or appropriate attributes can access it. For instance, the teacher may specify the following access structure for accessing the midterm result: “NTU” AND (“Teacher” OR (“Student” AND “Computer Science”)). By this, the midterm result should only be seen by the Computer Science Department's students or the teacher himself. Furthermore, both of them are asked for being a member of NTU. In comparison with KPABE, CP-ABE is more appropriate for being applied to applications with complicated access control requirement since it enables data owner to choose the access structure for deciding who can access the message.
As a result, many CP-ABE schemes have been proposed for various purposes, such as extending the functionality or improving the security or efficiency of the system. However, most of existing CP-ABE schemes in the literature have linear-size decryption keys. Linear-size decryption keys mean that the size of decryption keys is linearly proportional to the size of the number of involved attributes. This drawback prevents lightweight devices being used as the storage of decryption keys for a CP-ABE scheme, in practice.
For conquering this shortage, Guo, Mu, Susilo, Wong, and Varadharajan has proposed a CP-ABE scheme with constant-size keys for lightweight devices in [11]. In that work, a novel CP-ABE scheme, where the size of decryption keys is independent of the number of involved attributes, was proposed. The size of the decryption key in [11] can be as small as 672 bits, which is suitable for storing CP- ABE keys on lightweight devices.
3. Preliminaries
For the ease of explanation, some notations and preliminary backgrounds are respectively defined and briefly addressed in this Section, first.
3.1 Bilinear Pairing
Let G1 and G2be two elliptic curve based groups, and GT is an elliptic curve based multiplicative group. The three groups are of the same order p. Let g1 be a generator of G1 and g2 be a generator of G2, and e(g1, g2 )be a generator of GT. A bilinear pairing e: G1×G2→GT is an injective function with the following properties hold:
-
Bilinearity: For allg ε G1, h ε G2 and a,b ε Zp, we have
- Non-degeneracy: e(g,g)≠1
- Computability: There is an efficient algorithm to computee (g,h) for all g ε G1 and h ε G2
3.2 CP-ABE with constant-Size keys for lightweight devices
As described in 0, a CP-ABE scheme uses a binary vector to represent
an attribute set. For example, let n=4. The 4-bit string
3.2.1 Setup
Taking a security parameter λ and a universe attribute set {A1,A2,...,An} as input, the setup algorithm outputs a public key PK and a master secret key MSK. For a random number α ε Zp, the keys are respectively set as:
In (2),
3.2.2 Key generation
Taking an attribute set
and generate the secret key for
From the definitions of the function
3.2.3 Encrypt
Taking an access structure
and
Finally, the ciphertext CT is outputted as:
According to the definitions of polynomial functions
should be a polynomial, if
3.2.4 Decrypt
Taking a ciphertext CT, a public key PK and a secret key SK as
input, the decrypt algorithm outputs the message M or
We define Fiε Zp to be the coefficient of xi and set F0≠0. Second, we compute (U,V,W) as
Third, we get e(g,h)r by the function
Then, we compute the random number σ by
Finally, we extract the message M by the function
4. The Proposed Scheme
The proposed “Multi-User Searchable Encryption Scheme with Constant-Size Keys” is addressed in this Section.
4.1 Syetem Model
As shown in Figure 1, our system consists of four players: a trusted authority, a cloud server, a proxy server and a user/data owner.
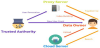
Trusted authority (TA): A trusted authority is in charge of the system setup, key generation and user revocation events. TA is fully trusted by all other players.
User (US)/Data owner (DO): This is an entity who wants to search data from or upload data to Cloud server. To upload data, DO builds the keyword index with the help of the proxy server, and encrypts the to-be-protected data. At last, DO uploads the encrypted index and the associated encrypted data to the Cloud server. To search a data, US or DO generates a trapdoor in cooperating with the proxy server, and then sends his trapdoor together with his attributes to the Cloud server.
Cloud server (CS): A Cloud server abounds with huge storage space and rich computational resources, which is usually operated by the Cloud service provider, such as Amazon and Microsoft.
Proxy server (PS): A proxy server is introduced to facilitate user’s secure usage of Cloud service, which can be deployed inside each enterprise (e.g., under the supervision of Chief Data Protection Officer of an organization). It helps data owners to build the keyword index and helps users to generate the trapdoor. Moreover, PS carries out the operation of user revocation when DO received a revocation order from TA.
4.2 System Operation Procedures
4.2.1 System Setup
At the beginning, a trusted authority calls Setup to obtain a public key PK and a master secret key MSK. Then he chooses a random number β ε Zp and sets Kmk= β as the search master key. After the generation of these three keys, the trusted authority sends the public key PK to a Cloud server and keeps the master secret key MSK and the search master key Kmk in secret.
4.2.2 New User Grant
When a user wants to join the system, the granting procedure is as follows:
- The trusted authority needs to select a unique identity ID for the user. Then, he has to assign and verify an attribute set associated with the user. The verification of attributes which are claimed by the user cannot be done automatically. Normally, it will be granted by asking the user to provide some proofs of his identity, such as student ID card number or organization's identity card number.
- After verifying of the attributes, the trusted authority calls Key Gen to generate a secret key SK for the user. For restricting the key size of the user, on the basis of the user ID, the trusted authority computes the control parameters AID and BID, which are ID and action-dependent (i.e., they are upload and/or search dependent), and also computes an attribute-set-dependent secret key SKA for the proxy server.
- The trusted authority randomly chooses a number μ ε Zp, and sets AID=μ.
-
After getting AID, the trusted authority uses the search master
key Kmk and AID to compute the other control parameter BID by
- Finally, the trusted authority transmits the tuple (ID,AID,SK) to the user and (ID,BID) to the proxy server. We can see that the tuple (ID,AID,SK), sent to the user, is independent of the number of involved attributes.
4.2.3 Keyword Index Building
Before uploading the encrypted file, a data owner has to build an encrypted keyword index with the help of the proxy server to let other users be able to search the files. The index building procedure is as follows.
- We assume D={d1,d2,…,dn} is the keyword set which is extractable from the stored files.
-
For all di ε D, data owner calculates
where yi ε Zp is a random number and H5 is a hash function that maps a keyword to a random element in G1.
- Data owner sends his ID and the tuple (T1,T2,…,Tn) to the proxy server.
- After receiving the search request, proxy server finds the corresponding BID associated with the received ID.
-
For all Ti, proxy server computes
and then transmits all Li back to the data owner.
-
Data owner computes
and then sets
-
Where Ri is a random number and
-
Finally, the keyword index set is set to be
4.2.4 Data Upload
After building the keyword index set, data owner randomly selects a symmetric key and encrypts the file by using a symmetric encryption algorithm such as AES. Then, data owner assigns an access structure and encrypts the key by running Encrypt. At last, he uploads the keyword index ID, the encrypted files, and the ciphertext of the symmetric key to Cloud server.
4.2.5 Search in the Encrypted Domain
When a request for searching the encrypted files, stored on the Cloud server, is received he has to do the following three steps (in sequence):
Step 1: Trapdoor Generation
We assume d is the keyword that the user wants to search, he should generate a trapdoor with the help of the proxy server. This step is executed as follows.
-
For the keyword d, the user calculates
then sends ID and Qd to the proxy server.
- After receiving the request, proxy server finds the corresponding BID according to ID.
-
Proxy server computes
and returns k' to the user.
Step 2: Attributes Verification
On receiving the request from a user, the cloud server has to verify the validity of attributes of the user. To verify attributes, the method we mentioned in Section 3 is applied. That is
should be a polynomial, if
Step 3: Search a Keyword
To search a keyword, Cloud server gets
4.2.6 File Decryption
After receiving the result from Cloud server, the user running Decrypt to extract the symmetric key, SK, which is used to encrypt the file. Then, the user can decrypt the file with the symmetric key.
4.2.7 User Revocation
Because of graduation, retirement or something else, when a user wants to leave the system, his search privilege should be revoked. After completing the verification by the trusted authority, he instructs the proxy server deleting the corresponding tuple (ID,BID). Without BID, the user is no longer able to search files stored on the Cloud server.
5. Security Analysis And Performance Evaluation
5.1 Security Analysis
5.1.1 Data Confidentiality
Data confidentiality is an important property of protected data, usually resulting from legislative measures, which prevents it from unauthorized disclosure. In our scheme, data must be confidential against Cloud server, unauthorized users and proxy server. Two encryption algorithms are adopted in our scheme. One is the symmetric encryption algorithm, such as AES, and another is CPABE with Constant-Size Keys for Lightweight Devices 0. AES has been proved that it is secure and 0 has also proved its security in the paper. Therefore, it is our belief that the proposed scheme is secure.
5.1.2 Keywords Confidentiality
The keyword must be kept confidential against any entity except for the data owner or the requesting user. Before sending ID and the tuple (T1,T2,…,Tn ) to proxy server while building keyword index, data owner calculates
Moreover, before sending ID and Qd to proxy server while generating trapdoor function, the user computes
for the keyword d. Because of the using of one-way hash function, proxy server or any other attackers cannot get any information about the stored keywords.
5.2 Performance Evaluation
5.2.1 Implementation Details
In our implementation, jpbc library is used to implement cryptographic operations. We select the Type-A Bilinear pairing. Type-A Bilinear pairing is the fastest pairing among all types of Elliptical curves, which is constructed on the curve Y2=X3+X over the field Fp for some prime p= 3 mod 4. Our system is realized by Java on a personal computer equipped with Intel(R) Core(TM) i7-4770 CPU @ 3.40GHz CPU under Windows10 OS.
5.2.2 Experimental Results
Clearly, from the above figure, timing cost for search depends on the total number of searched keywords. In Figure 2, the line “files” stands for the results of the data set which consists of 10000 files with 1 keyword per file, while the line “keywords” represents the data set which consists of only 1 file with 10000 keywords. While searching, we first locate the position of each file from the table. Then, we search keywords corresponding to the file. Due to the way of searching, the speed of the line “keywords” is a little bit faster than the line “files”. The higher cost for the upper case comes from the fact that it ran the search loop much more times than the bottom one. Take 10000 keywords as an example, the former just needs to find the position of the file one time but the latter needs to find it 10000 times. There is a point laying between the two lines, it stands for the data set which consists of 1000 files with 10 keywords. We can see that the speed of that point is in between of the two lines. In Figure 3, we see the timing cost for searching in the ciphertext domain is linearly proportional to the number of searched files while the timing costs for searching in the plaintext domain behaves almost the same. Notice that, the line “User cost” stands for the timing cost spent by the user. It is only a small and negligible portion of the total cost. In Fig. 3, the user is an authorized one and he is searching for all files. That is to say, he has searched 100000 files with 1 keyword by using 24494 milliseconds. It would be faster if the user doesn't have to or doesn't have the authority to search all 100000 files.


6. Conclusion And Fiture Work
Considering the practical problems of using SE schemes, we proposed and realized a multi-user searchable encryption scheme with constant-size keys. Lightweight devices usually have a limitedmemory storage, which could be too small to store large sized keys and/or large number of keys. In our work, we built a provably secure SE scheme which possesses a constant-size key property, that is, its length is independent of the number of file's attributes. The applicability of our system to lightweight devices has been justified by both analytical and experimental results. Since we have not done anything to the files stored on Cloud server, such as sorting or building trees, there is still some room remained for further improving the speed of searching. Of course, it will cost much more time while uploading than searching, as shown in our experiments. If we did something like building trees to the files stored on the Cloud server, it may spend more time while uploading the encrypted data; fortunately, this extra cost is usually endurable to the Cloud server. Therefore, it is worthy of finding a method which can improve the search speed but won’t increase too much time while uploading [20]. Of course, this is one of our future search directions.
Technical safeguards, involved with GDPR, include pseudonymization, encryption, and various capabilities for identifying and blocking data breaches, ensuring data security, and automatically identifying and classifying personal data, among others. It is important to note that a “data breach” according to the GDPR also includes “accidental or unlawful destruction, loss, alteration, unauthorized disclosure of, or access to, personal data transmitted, stored or otherwise processed”, and so preventing unauthorized use or access must also be considered as a key element of GDPR compliance. Since, in our system, all the stored data are encrypted and searchable; moreover, the access right can be specified by an access structure defined by the user or the trusted authority (i.e., under the supervision of the highest administrator of the organization), it is our belief that the proposed scheme can be viewed as one of the preliminary tools to deal with the looming enforcement of GDPR.
Competing Interests
The authors declare that they have no competing interests.