


1. Introduction
With the born of several blogging platforms (see for instance Wordpress1) users express their opinions on every kind of topics, from politic to religion, from marketing to product reviews, etc. This wealth of opinionated contents can be very useful to catch the user’s thought and perception. We are interested in analyzing opinions of OSS because of the nature of its selection. The software selection process, and particularly OSS, often includes a preliminary phase in which the potential users collect information about the products by surfing in blogs, forums and newsgroups. Thus, the process of selecting OSS very often involves a long and boring web search, looking into several forums, blogs and websites in order to extract as much information as possible.
For this reasons, we aim at understanding if we can apply opinion mining techniques, so as to support the OSS adoption process by understanding the general opinions on a given OSS.
The paper is structured as follow. In Section 2 we present background and related works. In Section 3 we summarize the approach used in this work. Section 4 we present a case study comparing our opinion mining approach with a set of opinion mining tools while in Section 5 discuss the results. Finally, in Section 6, we draw conclusions and we outline future works.
2. Background and Related Work
2.1 Open source adoption and adoption motivations
The definition of the information commonly used by the users when they evaluate OSS projects has been investigated in the last few years, and several OSS evaluation methods have been proposed [1-3]. The reasons and motivations that lead software companies to adopt or reject OSS and to understand how people can trust software. Moreover, several empirical works investigated the importance of OSS and the factors that bring to the OSS adoption.
In our previous work [4,5] we conducted a survey with 151 FLOSS stakeholders, with different roles and responsibilities, about the factors that they consider most important when assessing whether FLOSS is trustworthy. Here, we did not ask the motivations for the adoption of a FLOSS product or a proprietary one, but we asked for the factors considered to compare two FLOSS products.
We identified 37 factors, clustered in five groups: economic, license, development process, product quality, customer-oriented requirements and user opinions was considered of middle importance. Moreover, in another recent work, [6] we ran another survey to identify the recent motivations for the adoption of OSS and also in this case, the opinions were also considered as important. Results are also confirmed by several empirical study such as [7-13]. The idea of using opinion mining techniques have been proposed in several work [13,14] Based on the aforementioned work, we believe that the investigation of an automated opinion extraction tool would be valuable for OSS users [6].
2.2 Opinion mining and sentiment analysis approaches
Recently, a good deal of work has been done by researchers on sentiment analysis (or polarity analysis) of reviews and opinion mining. Opinion mining is an important step where researchers try to understand if a text contains an opinion while Sentiment Analysis is a step further, involving polarity analysis detecting if an opinion is positive or negative.
Typically, the methods employed include combinations of machine learning and shallow natural language processing methods, and achieve good accuracy [15]. For instance, a study showed that peaks in references to books in weblogs are likely to be followed by peaks in their sales [16].
The year 2001 or so, seems to be the beginning of widespread awareness of the research problems and opportunities that sentiment analysis and opinion mining raise. Factors behind this widespread include the rise of machine learning methods in natural language processing and information retrieval, the availability of dataset for machine learning algorithms to be trained. In 2002, Bo Pang and Lillian Lee [17], applied three Machine Learning techniques on the Movie review Domain:
Support Vector Machines (SVMs), Naive Bayes and Maximum Entropy. They tested the algorithms on unigrams and bigrams, appending POS tags to every word via Oliver Mason’s QTag program [18]. This serves a crude form of word sense disambiguation distinguishing the different usage of words (e.g. the difference in usages of the word ”love” in ”I love this movie” versus ”This is a love story”. They looked at the performance of using adjectives alone, discovering that adjectives provided a less useful information then unigram presence. Indeed, simply using the most frequent unigrams presence information turned out to be the most effective way to spot opinions in text, yielding performance comparable to that using the presence of all lines. In terms of relative performance, Naive Bayes tend to the worst while Support Vector Machines tend to the best. An important problem come out from this paper was the needs of the identification of some kind of features indicating weather sentences are on topic.
Since 1992, the born of challenges (see for instance TREC2 and SIGIR3) encourage research within the information retrieval community by providing the infrastructure necessary for largescale evaluation of text retrieval methodologies. For Example, each year, TREC provides a test set of documents and questions on which participants can run their own retrieval systems, and return a list of the retrieved top-ranked documents. Then, TREC collect and judges the retrieved documents for correctness, and evaluates the results. The TREC cycle ends with a workshop that is a forum for participants to share their experiences. TREC and other similar contexts help significantly the community in improve their Information Retrieval algorithms by means of the comparison of the results of several people on the same problem. The vast majority of Opinion Mining techniques applied a 3-step algorithm. In [19] Zhang et al, first decompose documents in sentences, then labeled each sentence with an opinion score by means of a classifier. Sequently they labeled the text if it contains at least one opinionated sentence. Yang et al in [20] also considered multiple sources of evidence in their opinion retrieval steps by combining scores from opinion detection based on a common opinions terms. Then they built a lexicon by identifying the most occurring terms. Sequently, the opinion terms are manually labeled by assigning an opinion weight. They identify also the low frequency terms score, and acronyms score. Moreover, they combined the obtained each score as a weighted sum and they used this sum as training data. Finally in the third step, the linear combination of relevance and opinion score is used to score and rank documents. In another paper, Zhang et al. [21] used the Classification by Minimizing Errors (CME) to assign an opinion to each sentence of a blog post. They assigned an opinion score to each document by means of an SVN classifier, based on the values of the defined features. They used a set of movie review4 to train the CME classifier and they used a labelled dataset for classifying documents by means of SVM. The blog posts were ranked by the final score that was calculated as the relevance score times the opinion score.
Our work differs from existing studies of sentiment analysis and business data in two important aspects. First, our domain includes weblogs from several sources i.e., a set of domains which tend to be far less focused and organized than the typical product review data targeted by sentiment analyzers, and consist predominantly of informal and unorganized text. Second, we aim at applying this study as a specific means to understand if the opinion of the OSS community on an OSS product reflects the software quality.
3. The Study Approach
In this section we summarize the approach adopted for this case study. We first extract the relevant blog post from existing search engines, then we run the distillation task, to retrieve only the “opinionated” content, and finally we apply the opinion retrieval technique.
3.1 Web crawling
In order to build data-set containing posts that express an opinion about a particular topic, we developed a web crawler that queries blog search engines (like Technorati5 and Google log Search6) every day, extracting the list of relevant posts for a given topic.
Each data-set includes an xml index summarizing each post, a folder containing all html pages, and a database dump with some meta-information. The crawler stores all post information on a relational database to speed up the post selection up by means of SQL queries. Furthermore, the crawler extracts pages by using the same format of TREC, so the application of techniques developed in TREC can be quickly applied to the generated data-sets.
3.2 Blog distillation
Blog search users often wish to identify blogs about a given topic so that they can subscribe to them and read them on a regular basis [22]. The blog distillation task can be defined as: ”Find me a blog with a principle, recurring interest in the topic X.” Systems should suggest feeds that are principally devoted to the topic over the time span of the feed, and would be recommended to a user as an interesting feed about the topic (i.e. a user may be interested in adding it to his RSS reader).
The blog distillation task has been approached from many different points of view. In [23], the authors view the distillation task as an as ad-hoc search and they consider each blog as a long document created by concatenating all postings together. Other researchers treat it as the resource ranking problem in federated search [24]. They view the blog search problem as the task of ranking collections of blog posts rather than single documents. A similar approach has been used in [25], where they consider a blog as a collection of postings and use resource selection approaches. Their intuition is that finding relevant blogs is similar to finding relevant collections in a distributed search environment. In [22], the authors modeled blog distillation as an expert search problem and use a voting model for tackling it.
Our intuition is that each post in a blog provides evidence regarding the relevancy of that blog to a specific topic. Blogs with more (positive) evidence are more likely to be relevant. Moreover, each post has many different features like content, in links, and anchor text that can be used to estimate relevancy. There are also global features of each blog like the total number of posts, the number of postings that are relevant to the topic and the cohesiveness of the blog that could be useful to consider.
Our first approach is to create a baseline for blog distillation system that uses only the content of blog posts as a source of evidence. To do this, we consider the expert search idea proposed in [26]. The main idea of that work is to treat blogs as experts and feed distillation as expert search. In the expert search task, systems are asked to rank candidate experts with respect to their predicted expertise about a query, using documentary evidence of expertise found in the collection. So the idea is that the blog distillation task can be seen as a voting process: A blogger with an interest in a topic would send a post regularly about the topic, and these blog posts would be retrieved in response to the query. Each time a blog post is retrieved, it can be seen as a vote for that blog as being relevant to (an expert in) the topic area. We use the voting model to find relevant blogs. The model ranks blogs by considering the sum of the exponential of the relevance scores of the postings associated with each blog. The model is one of the data fusion models which Macdonald and Ounis used in their expert search system [27]. For our second approach, we used more features to represent each blog beside its content. To take the different features into account, we use a Rank Learning approach [28] to combine the features into a single retrieval function. Useful features are:
- Cohesiveness of blog postings
- Number of postings
- Number of relevant postings (posts in top N relevance results)
- Number of in links
- Relevance of in link post content
- Relevance of in link anchor-text
3.3 Opinion mining
In the Opinion Retrieval task, we adopt the approach defined in [29]. Here, we report on the main steps of the approach. More details can be found in [29]. The approach is composed by 2 steps: First we index the collection, then we combine additional information, including the content of incoming hyperlinks and tag data from social bookmarking websites with our basic retrieval method (Divergence from Randomness version of BM25 (DFR BM25) (Table 1) [17].

The collection indexing phase is carried out by means of Terrier Information Retrieval system [30]. We extended this content-based retrieval technique with additional information including the content of incoming hyperlinks and tag data from social bookmarking websites. The latter has been shown to be useful for improving Web Search [26,31-33].
Our approach to ranking blog posts by their opinion level relies on a learning framework [28,34]. We trained a Learning to Rank system to take both a relevance score (output by the rank learner described above) and an ”opinion score” for each document into account when producing an output ranking. The advantage of this approach is that we do not need to explicitly decide how to combine these forms of evidence, but can rely on historical data for fine tuning the retrieval.
The problem is to estimate a score for the”opinion atedness” of each document. We have two approaches to doing this. In the first approach, we calculate an opinion score for each term in the document and then we combine the score over all terms in the document. In the second, we train a classification system to distinguish between opinionated and non-opinionated posts. Then, we use the confidence of the classifier as an opinion score for the document.
The opinion score is then calculated with two methods. The first method considers the technique proposed by Amati [35] and the Kullback-Leibler divergence [36] between the opinionated document set and the relevant document set as:
Opinion1(d) = ∑t∈d opinion(t)p(t|d)
where p(t|d) is the relative frequency of term t in the document d.
As second opinion retrieval method, we trained a Support Vector Machine (SVM) to recognize opinionated documents. We can then use the confidence of the classifier (i.e. the distance from the hyperplane) as the opinion score for each document. The per term opinion score is used in this case only for feature selection, As second opinion retrieval method, we trained a Support Vector Machine (SVM) to recognize opinionated documents. We can then use the confidence of the classifier (i.e. the distance from the hyperplane) as the opinion score for each document. The per term opinion score is used in this case only for feature selection,
Opinion_SVM(d) = fSVM(p(t1|d),..., p(tm|d))
4. Results
In this section, we describe the results of the application of our approach to a set of OSS projects with our opinion mining techniques (Opin1 and OpinSVM) and four of the most common opinion mining tools:
- Python NLTK Text Classification5
- Vivekl6
- SentiStrenght7
- SentiRank8
The goal is to understand the power of our techniques, compared with existing ones, so as to understand if using a generic tool, not trained for our purpose, would provide similar results.
4.1 OSS data-set building
The first step to be carried out is the selection of project and the online extraction of user generated content. The selection of projects addressed different types of software applications, generally considered stable and mature. The complete set of projects comprises 27 products, having different characteristics:
- There are different types of programs and applications (from web servers to operating system, from libraries to content management systems).
- The communities of developers and users have different sizes.
- The projects have different ages.
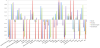
During the selection it was taken care that every factor value was present in the set of projects. The crawler ran for 4 months, collecting a total of 78531 posts with thousands of posts for each OSS project. In Table 3 we show the projects list and the number of posts extracted together with the average sentiment obtained by each approach adopted in Section 5. In Figure 1 we show the trend of the number of posts retrieved in the same period.
In Figure 1 we can see an interesting trend for each project, considering the number of extracted post per day. What we can clearly see is that there are no major intersections and all projects follow a similar trend. We reserve the possibility of more investigation in future works.

4.2 Opinion mining
In order to evaluate the results, we manually labelled 2700 posts (100 per project) Here we first apply the tools and techniques to the whole data-set, in order to compare the resulting polarity of each post. Then we apply again the tools on a manually labelled analyze reported Results for the polarity obtained by means of the application of the Python NLTK tool to our complete data-set are presented in Table 3 while results for precision and recall for the labelled data-set are reported in Table 4.
4.3 Opin1 and OpinSVN
Here we report on the application of our first approaches as reported in Section 3. In order to calculate the opinion score for documents we used the expected opinionatedness of words in documents as described in Section 3. In OpinSVM we also used the confidence of the trained SVM to find the opinion score of the documents. We used the classifier to classify test document. The confidence of the classifier was then used as opinion score for documents.
Finally, we combine relevance and opinion score (from step 4) by means of SVM and we produce the final ranking. The collection indexing was carried out by means of Terrier Information Retrieval system [30]. Like in Section 2, we used the Divergence from Randomness version of BM25 (DFR BM25) weighting model to compute a score for each blog post.
The average precision of the Opin1 approach is 73% while the recall is 63% while for the OpinSVM approach we obtained a precision of 76% and a recall of 72%.
Finally, we tested the models (Opinion1 and Opinion SVM) by using the TREC’08 training data, so as to evaluate the capability of the algorithm of classifying opinions with a system trained on a different domain. As expected, in this case, the result show of a very low precision and recall (precision=0.66, recall=0.53). The reason is possibly due to the data-set itself. The TREC’08 data-set is composed by a heterogeneous set of topics, ranging from politics to science, from news to art. Our data-set is domain specific and need an adhoc training set to be set-up. We also think that a disadvantage of our”multiple-levels of learning” approach is that we cannot maximize the use of training data because of its unavailability.
4.4 Python NLTK
The Python NLTK (NLTK) Text Classification applies an over 50 corpora and 10 lexical resources such as WordNet, along with a suite of text processing libraries for classification, tokenization, stemming, tagging, parsing, and semantic reasoning, wrappers for industrialstrength NLP libraries, and an active discussion forum. It provides positive and negative polarity results that ranges from 0 to 1. The application to our trained data-set report a precision of 43% and a recall of 17%.
4.5 Vivekn
Vivekn is based on a Naïve Bayes classifier and it examines individual words and short sequences of words (n-grams) and comparing them with a probability model. The probability model is built on a labelled data-set of IMDb movie reviews. It provides results with 3 possible labels, positive, negative or neutral, together with a confidence interval. The application to our trained data-set report a precision of 40% and a recall of 20%.
4.6 SentiStrength
SentiStrength [37] estimates the strength of positive and negative sentiment in short texts, even for informal language. It claims to have a human-level accuracy for short social web texts in English, except for political texts.
SentiStrength reports values that range from -5 (extremely negative) to +5 (extremely positive). The application to our trained data-set report a precision of 45% and a recall of 24%.
4.7 SentiRank
SentiRank uses a proprietary algorithm, which uses unspecified linguistic rules todetermine the sentiment. Results are presented with different ranges where values from -10 to 5 represent very negative results, values from -4.99 to -1 are related to negative opinions, values from -0.99 to +0.99 to neutral opinions, 1 to 4.99 for positive and finally from 5 to 10 for very positive opinions. The application to our trained data-set report a precision of 55% and a recall of 35%.
5. Results Comparison
The selected approached and tools apply different algorithms, based on different trained data-sets. In order to compare the results, we analyze all post in our labeled data-set for each project with all tools and we normalized results with a scale that ranges from -1 (very negative) to +1 (very positive). In case of Vivekn, we assigned -1 to negative content, 0 to neutral and +1 but we also report the confidence level.
As expected, the results obtained from out techniques always identify the polarity more accurately, compared to the other tools. We believe this is due to the training on a domain-specific data-set (Table 3). Moreover, as we can see from Table 3 and Figure 2, results obtained from the four tools provide non homogeneous polarity results. Opin1 and OpinSVM always provide the same polarity while also NLTK provides a similar polarity of SentiStrenght. This again, can be due to the fact that the tools have been trained with a set of common datasets. Vivekn and SentiStrenght often provide divergent results from the other tools [38-40].
6. Conclusion
In this work we investigated is is possible to use the actual opinion mining techniques to support the Open Source Software (OSS) adoption process. The goal is to understand if users can rely on opinions automatically collected from forums, so as to get an overall overview of the common opinion on a possible OSS they are interesting to adopt.
In this paper, we first developed a web crawler to extract user generated content online on 27 well known OSS projects from blogs and forum. We ran the crawler for four months, extracting 88K blog posts and then we evaluate the opinions of OSS users expressed in the documents. In order to evaluate the accuracy of the results, we manually labelled the relevance and the polarity of 2700 retrieved documents (100 per project). Then we compared the result obtained with four of the most common Opinion Mining tools with our proposed approaches [41-43].
Results show that our approach identifies the opinions with an acceptable accuracy (precision = 76% and recall=72%). The application of existing opinion mining tools provide very discordant results, only in few cases all the tools provide the same polarity for all the texts analyzed, reporting a very low precision and recall.
We believe that the application of our approach provides the better results compared to the other tools, mainly because it has been trained on a labelled dataset on the OSS domain.
Considering the application of our approach to the set of OSS projects, we find out that, at the moment, the opinion retrieval technique we adopted in TREC’08 [29] could be applicable to assess opinions on OSS project review, so as to help users to get a general overview on other users’ opinions. Considering the other tools used in this study, we believe that, since they are claimed to be able to predict opinions with human-level accuracy, the reason of negative result is due to the fact that the actual opinion mining techniques has been designed for different domains and trained on different data-sets.
In order to rely on the Opinion Mining frameworks, our future work include the application of different opinion mining technique, and the development of an online tool to directly support users in the OSS evaluation.
Author Contributions
Conceived and designed the experiments: DT. Analyzed the data: DT. Wrote the first draft of the manuscript: DT. Contributed to the writing of the manuscript: DT. Agree with manuscript results and conclusions: DT. Jointly developed the structure and arguments for the paper: DT. Made critical revisions and approved final version: DT.
All authors reviewed and approved of the final manuscript.
Acknowledgments
We are deeply indebted to and would like to thank University of Lugano, in quality of Prof. Fabio Crestani, Shima Gerani and Mark Carman for the collaboration in this work.
Disclosures and Ethics
As a requirement of publication author(s) have provided to the publisher signed confirmation of compliance with legal and ethical obligations including but not limited to the following: authorship and contributorship, conflicts of interest, privacy and confidentiality and (where applicable) protection of human and animal research subjects.
The authors have read and confirmed their agreement with the ICMJE authorship and conflict of interest criteria. The authors have also confirmed that this article is unique and not under consideration or published in any other publication, and that they have permission from rights holders to reproduce any copyrighted material. Any disclosures are made in this section. The external blind peer reviewers report no conflicts of interest.