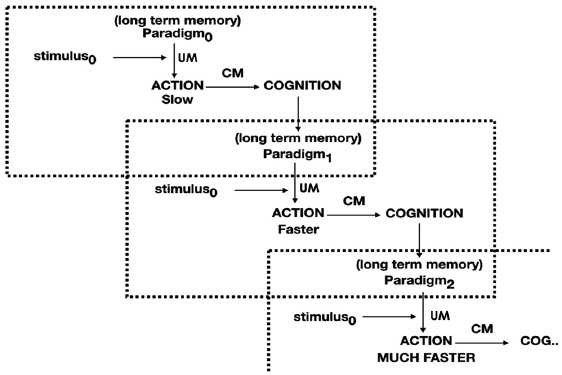
Figure 1: The Bignetti Model (TBM). UM reacts to a stimulus by choosing in LTM archives the most adequate paradigm within those used in the past. Then, CM receives the feed-back information of the action outcomes; among them, CM can extrapolate useful indications to update LTM. By repeating this protocol several times, the memorized paradigms become more and more efficient so the reaction outcomes progressively ameliorate (the success probability increases and the required time shorten).