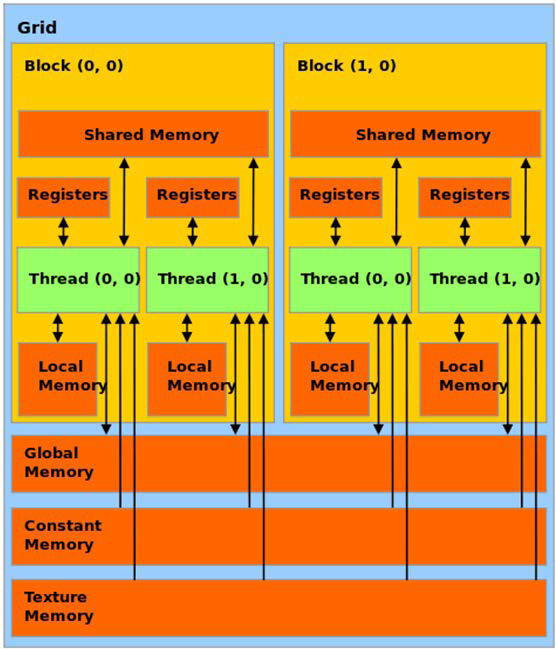
Figure 1: CUDA memory model of a GPU grid. Threads can access the Global and Constant memories all the time, but calculations of sets of threads are performed on local memory. Image obtained from https://commons.wikimedia.org/wiki/File:Memory.svg (CC-BY-3.0).